IBM Cloud Pak for Automation helps businesses boost their efficiency by automating and streamlining complex processes. The platform includes a low-code application builder to create UIs to be powered by IBM automation services.
The Cloud Pak intially only included experiences to design and build automated decision and workflow services to power these applications. IBM's existing tools for document processing were complex and required expert IT resources to set up and update. There was a need for a tool that could build document processing solutions within the Cloud Pak framework and be accessible to users without techincal expertise.
IBM Automation Document Processing
Product Design, Visual Design
Designed a new experience which empowers business users to train machine learning models for document classification and data extraction.
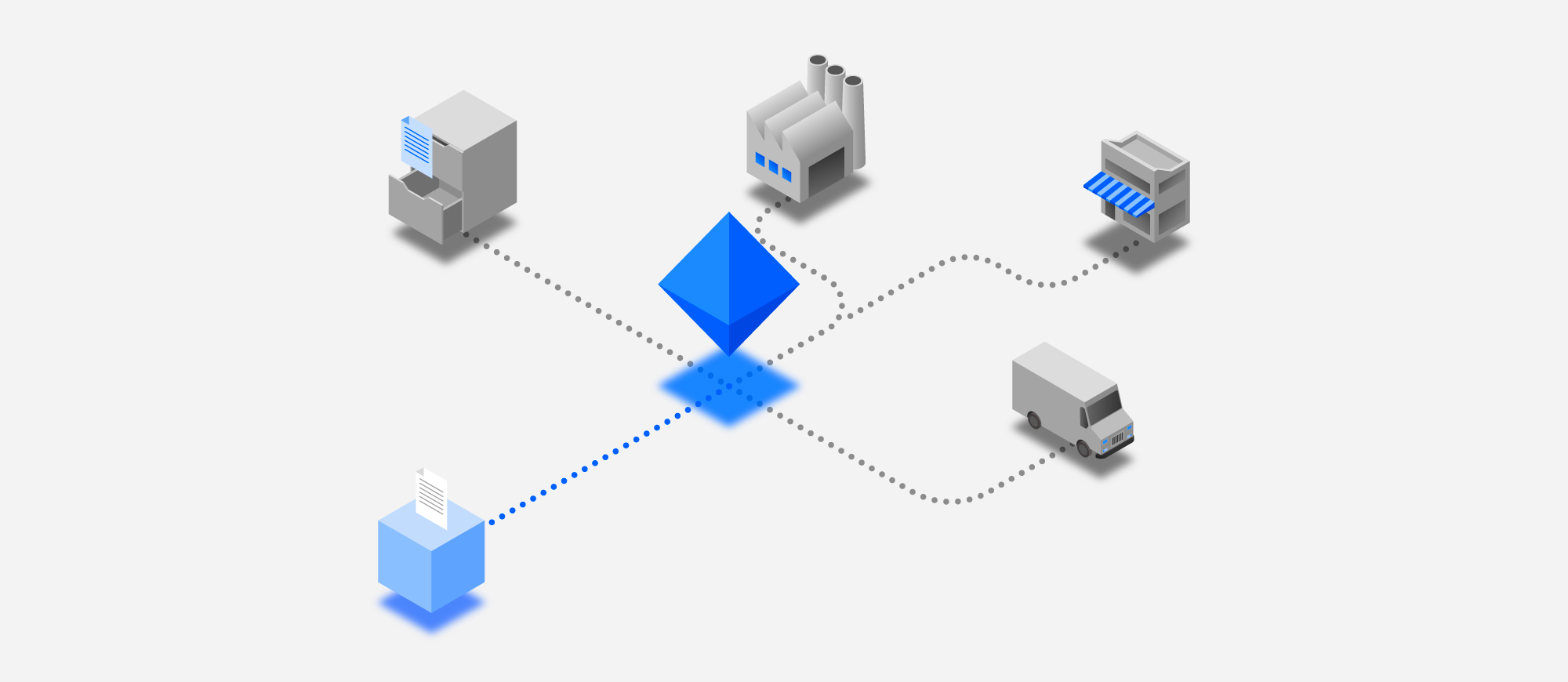
The business context
Why automate document processing?
Here's an example scenario: A large corporation called Bitty Box Co. fulfills orders through a supplier called Supply Co. Without a digital solution, handling the details of the items received and the invoice processing can be labor intensive and time consuming.
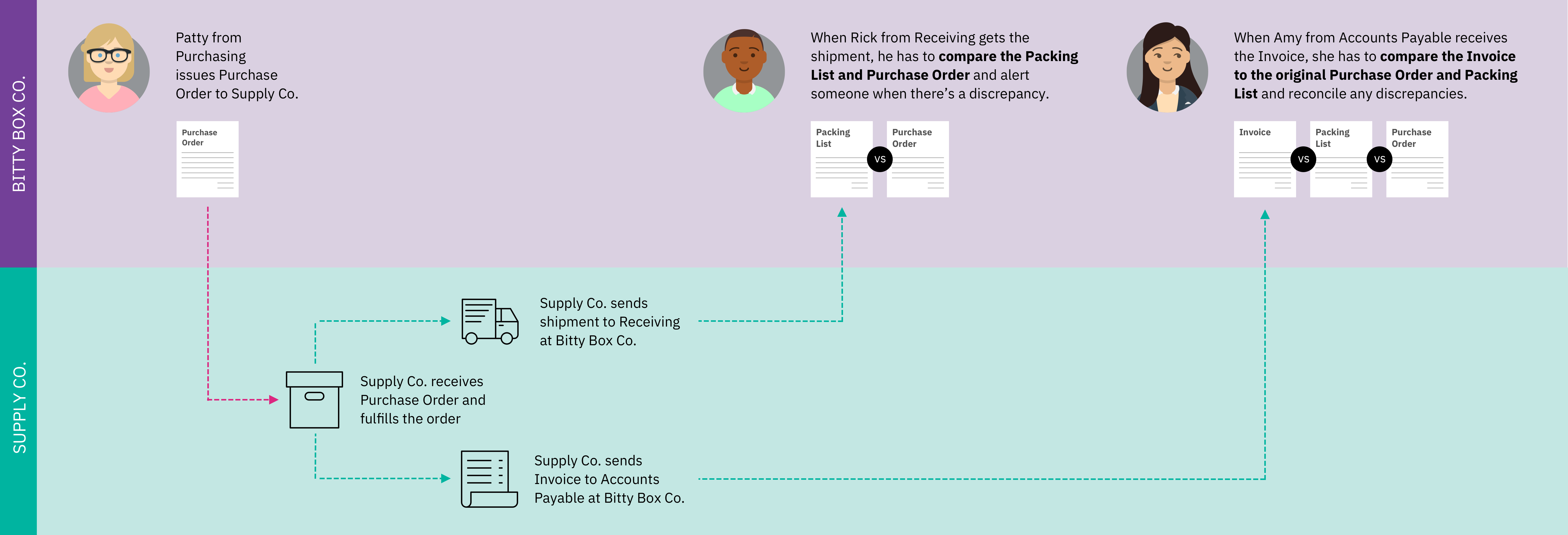
The goal
As part of the Cloud Pak, we envisioned a new tool - Automation Document Processing - (or ADP) which could
- Expedite document classification and data extraction using sample documents and machine learning
- Be accessible to any business user, without and coding or data science expertise needed
The workshop
We started by having a design thinking workshop with product managers, architects, and developers to map out the high-level customer journey. During these interactive sessions I was also able to glean the technical requirements of the model training.

The user journey
Following the workshop I started diagramming the user journey in detail to map out the different screens, states, and possible edge cases. I like envision the user journey from an abstract level before getting into the specific UI details.
 by Sapna Patel
by Sapna Patel

You will be able to edit this mural.
Competitive research
I did research on products in an adjacent market - image classification - to see what patterns I could observe in their no-code machine learning experiences to leverage. I learned that breaking up the process into distinct teach, train, and test phases would give users simple and focused tasks. I applied this pattern to both the document classification and data extraction model flows in ADP.
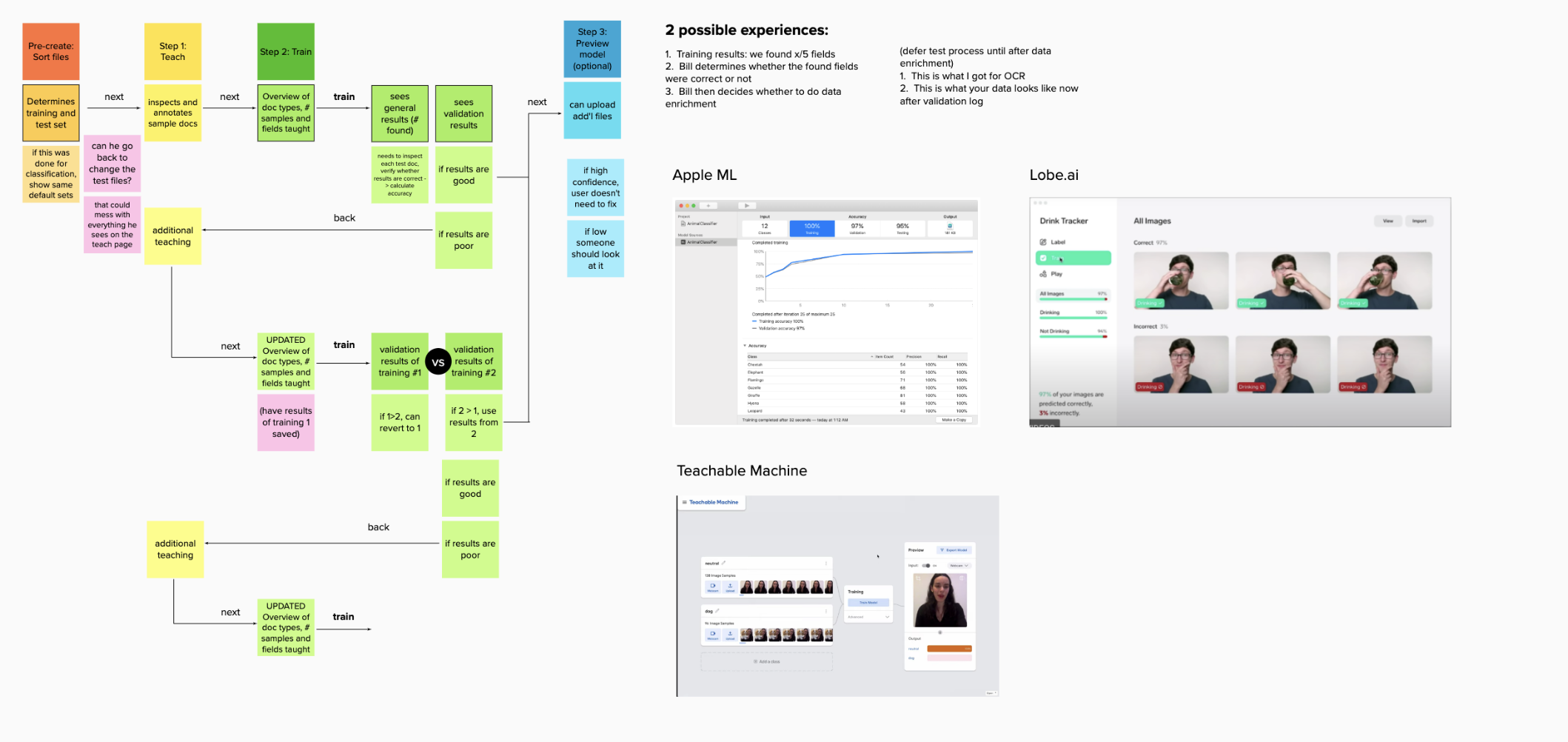
Wireframing
After iterating through the high livel journey with stakeholders, I created low-fidelity wireframes to brainstorm UI patterns and consider their tradeoffs. I regularly shared my concepts with product managers and engineers to validate their business value, test their teachnical feasability, and to gather feedback to help me pivot and iterate when necessary.
New interaction patterns
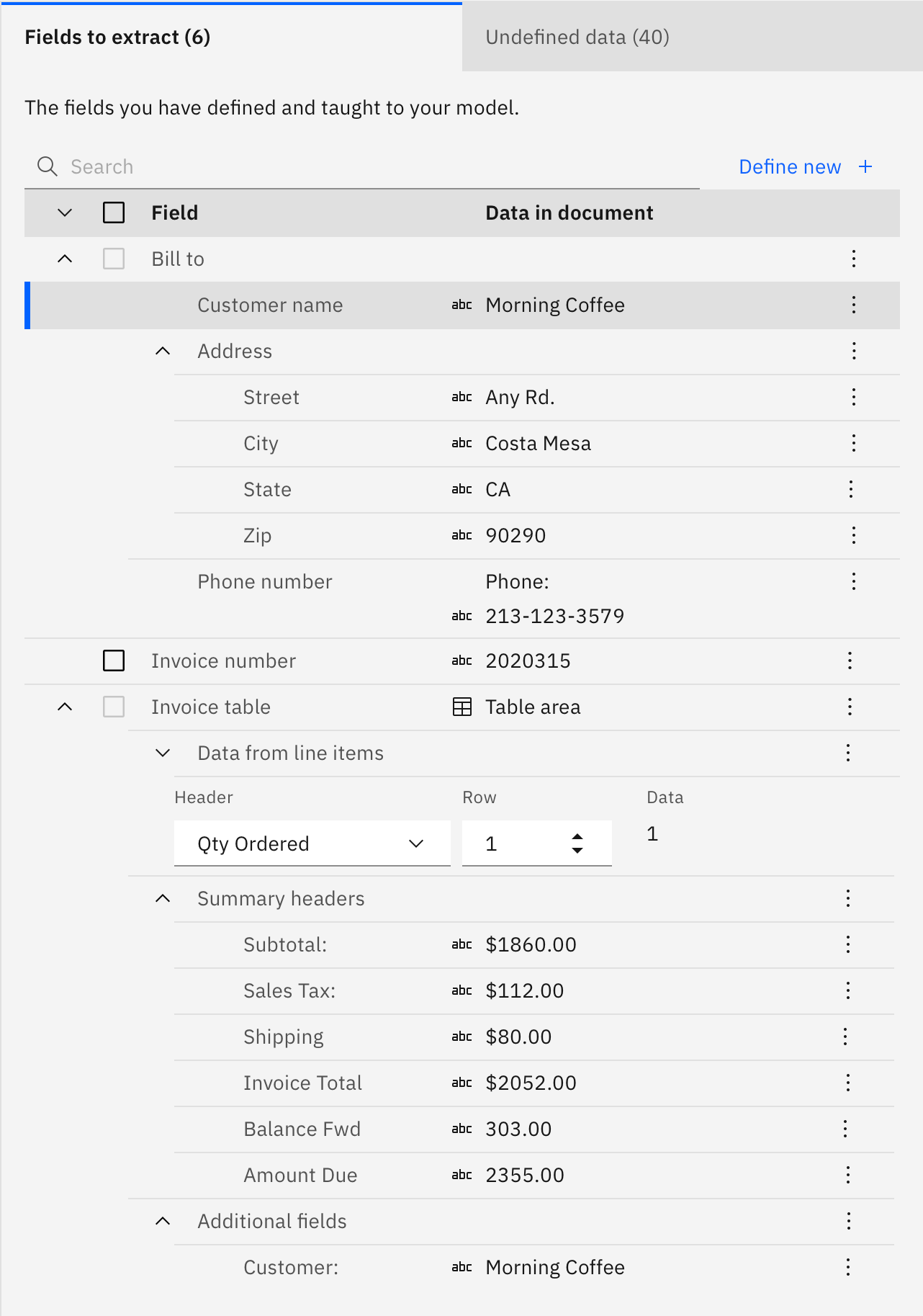
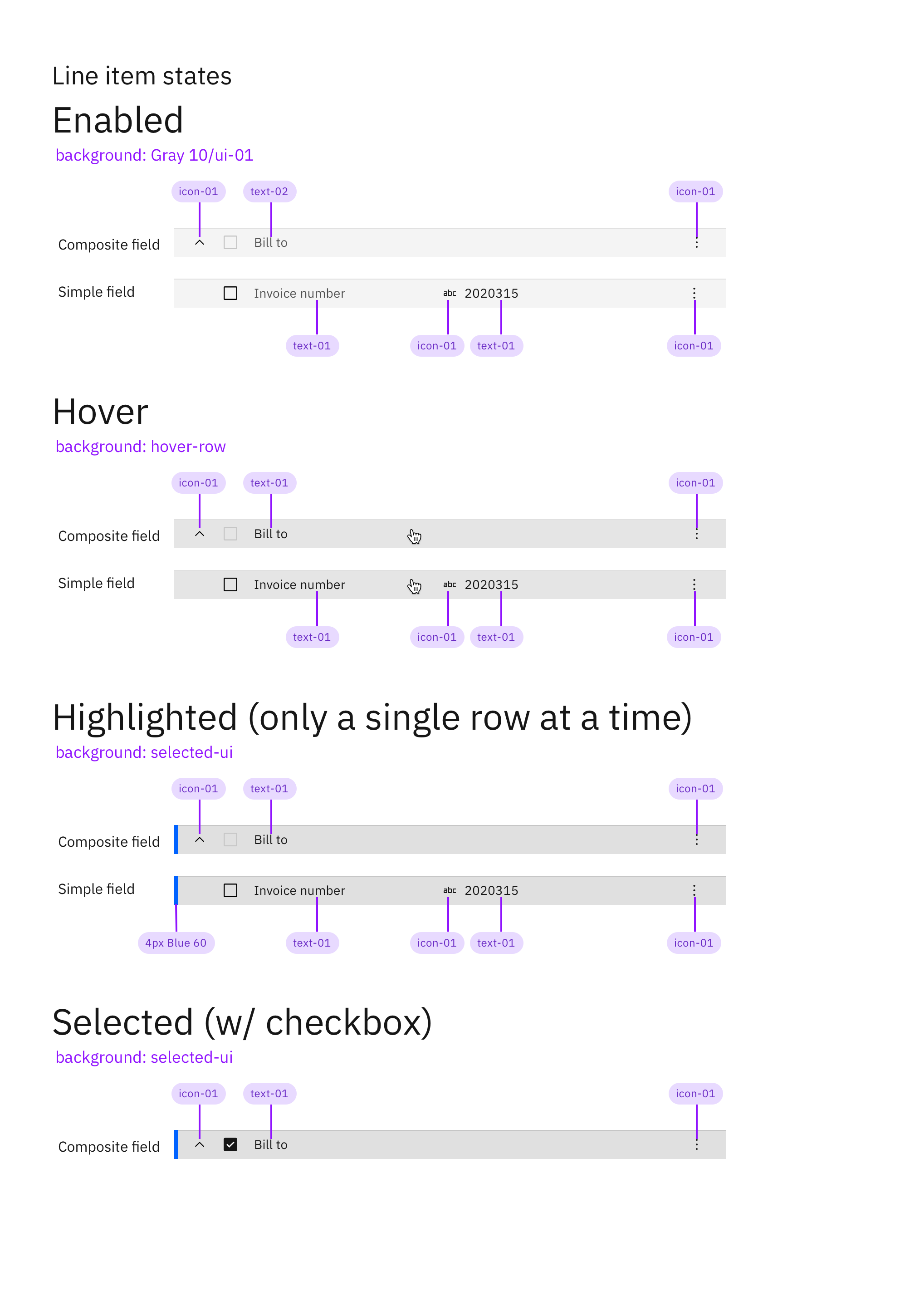
We used IBM's Carbon design system as the basis for all of our UI patterns and interactions. I had to exapnd upon some the base components to accomodate some of our products complex functionality while staying aligned to the IBM Design brand. Below is an example of how I evolved Carbon's data table to display multiple levels of hierarchy for complex data.
Final designs
Below are a few of the completed mockups. You can also check out a click-through prototype here.
Landing page
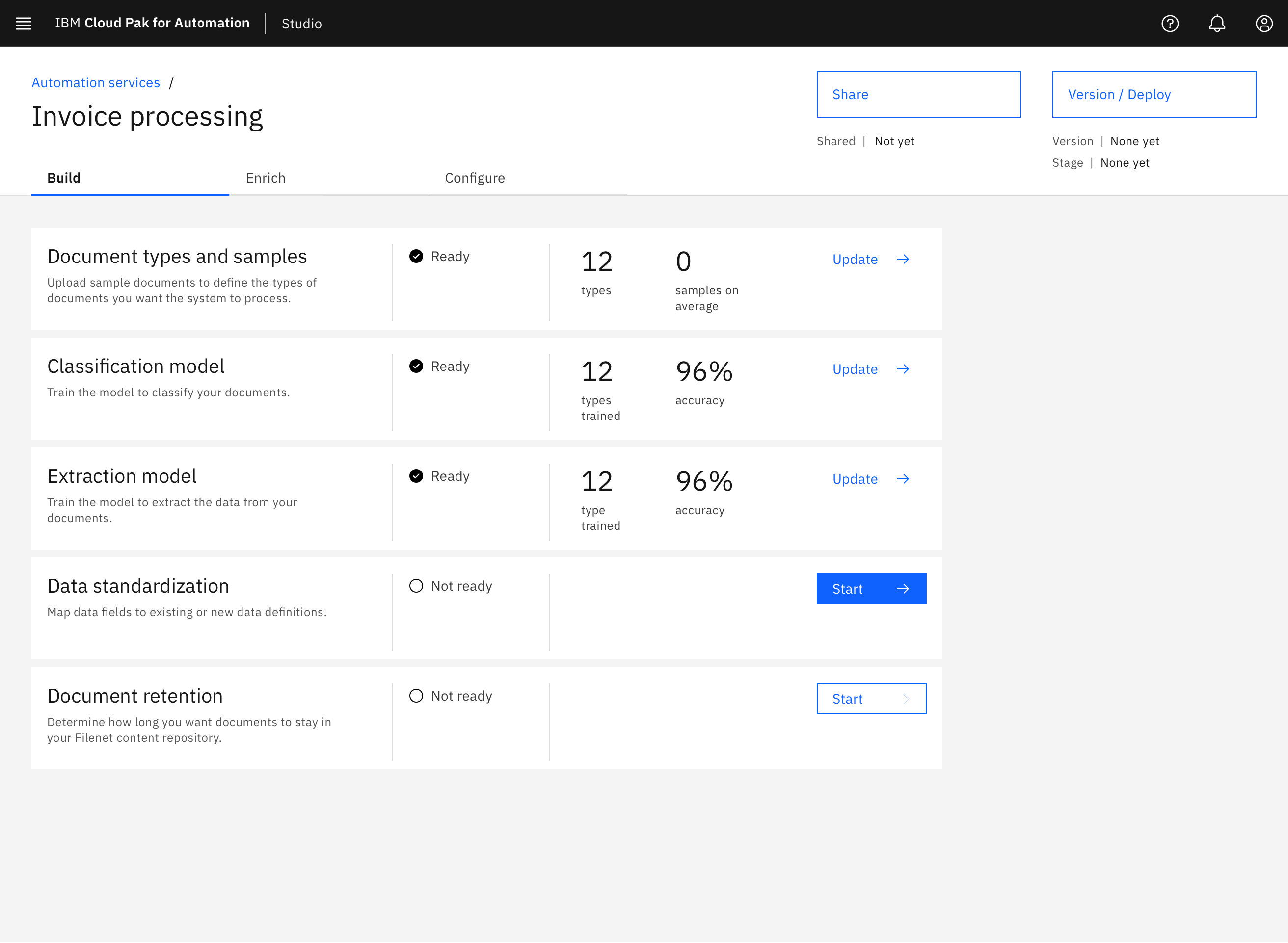
When a business user starts working on a new document processing project, there are several tasks that they need to complete in a certain order. I designed this landing page to keep users aware of where they are in the process and where they should focus their attention next. Segmenting their experience into these 5 distinct tasks lessens their cognitive load at any given time.
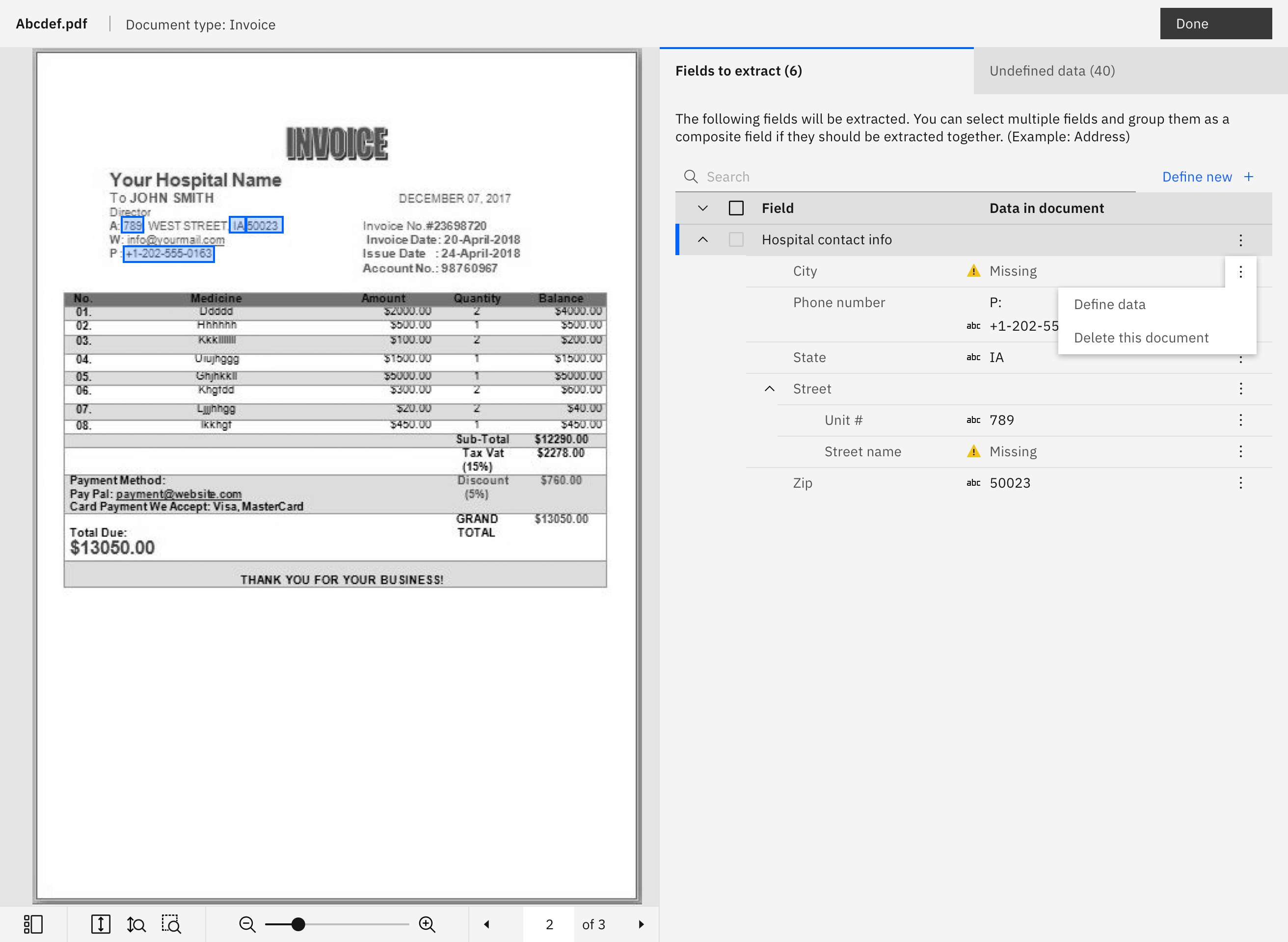
Teach the extraction model
From my competitive research I learned to keep the model training processing simple by breaking up the process into teach, train, and test phases. I broke this up further by having users focus on teaching data extraction for specific document types at a time to help them acheive accurate model results faster.
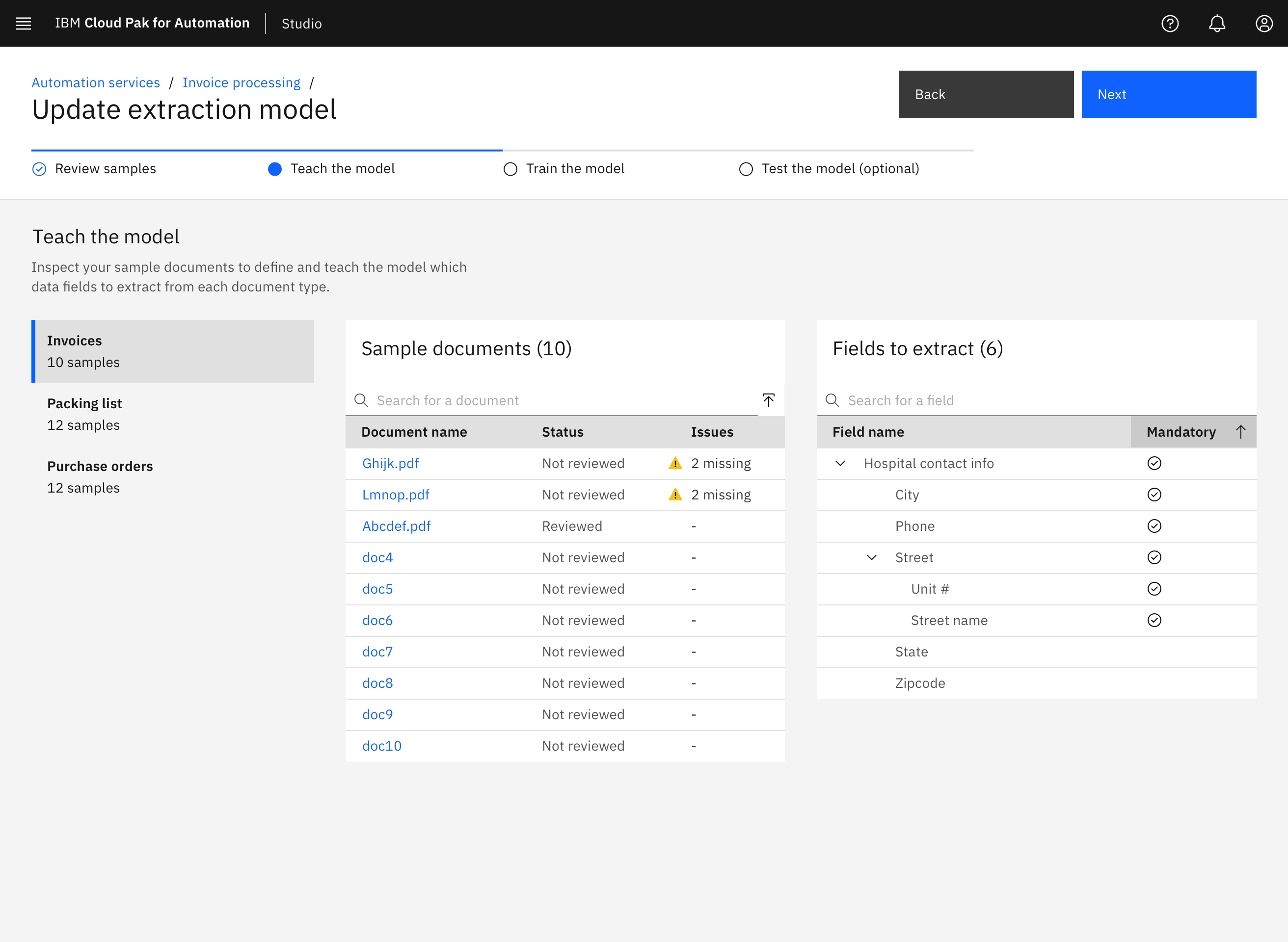
Leveraging sample documents
To reduce the amount of manual input needed, the experience of teaching the extraction model heavily leverages the data available in the user's own sample documents. By interacting directly with documents, users can easily click and drag to identify the pieces of data they would like the model to learn to extract.
User testing results
Using the click-through prototype, our research team conducted a remote moderated usability study of the data extraction training portion of the experience. The goal was to evaluate the ease of use for completing specific data extraction tasks.
- Qualifying criteria of participants included business roles like process improvement professionals and automation builders. Those with technical expertise like solutions architects and data scientists were specifically disqualified.
- 6 participants were asked to complete 6 data extraction tasks using the Automation Document Processing interface
- Task completion rate was 94% across all participants
The results demonstrated general success in designing an easily navigable and understandable experience for our targeted demographic of business users.